
I was in sunny Edmonton last week, giving a paper at the University of Alberta on the ethics of physician billing. (I always enjoy being back in any part of the country where the sky occupies what I consider to be the correct proportion of one’s visual field, i.e., approximately 2/3rds.) The paper can be found here, for those who are interested. In it, I basically complain about the failure of the medical profession to treat billing as an “ethics” issue. Instead, the profession tolerates, and in some case encourages, a “compliance-based” culture, where any strategy that falls short of outright fraud is essentially considered acceptable.
There is a bunch of subtle argumentation in the paper about why billing should rightly be regarded as an issue of professional ethics, and not merely personal integrity. There are also a bunch of great examples of gamesmanship – a topic that is of perennial interest to me. (One example: surgeons are paid a premium for operating on patients who are morbidly obese, which means having a BMI greater than 40. Sometimes, after weighing a patient, they will find that the patient falls just short of the mark, having perhaps a BMI of 39.5. In that case, as one practitioner put it, “I just give them a couple glasses of water to drink and weigh them again.”)
In any case, the presentation also gave me the opportunity to present an awesome graphic, which is taken from a paper by Ben Chan, Geoffrey M. Anderson and Marc-Erick Thériault (“Fee Code Creep Among General Practitioners and Family Physicians in Ontario: Why Does the Ratio of Intermediate to Minor Assessments Keep Climbing?” Canadian Medical Association Journal, 158 (1998): 749-54.) The paper deals with the phenomenon of “upcoding,” which occurs when physicians are given several ways of “coding” a procedure for billing purposes, perhaps described in slightly vague terms, and so shift over time toward always billing the more expensive codes.
The example they study is the general primary care assessment in Ontario, which allows for billing either a “minor” or an “intermediate” assessment (the former, at the time they wrote the paper, was worth $16.25, while the latter was valued at $24.80). Since it is pretty much impossible to verify which assessment was conducted, there is a temptation here for physicians to “upcode,” by billing the intermediate assessment when in fact they have only conducted a minor one. So what Chan, Anderson and Thériault did was simply go through the database that records all payments to physicians in Ontario and calculate the ratio of intermediate to minor assessments billed by primary care physicians. The distribution looks like this:
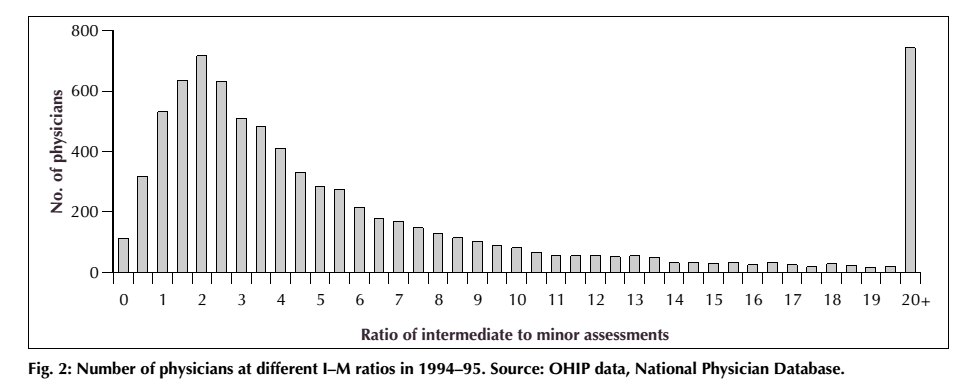
It’s pretty easy to see what’s going on here. On the left, we have the normal-ish distribution that one would expect to see, among physicians who are by-and-large being honest in their billing practices. One sees there a median ratio of about 2 intermediate assessments for every 1 minor one. And over on the far right-hand side there is an obvious anomaly – a huge number of physicians billing more than 20 intermediate assessments for every 1 minor one. Not so difficult to figure out who is abusing the code!
Ethics aside, I think any physician who is not being entirely forthright in his or her billing practices, and who looks at a graph like this, should start to become extremely nervous. At the moment, the Ministry of Health and Long-Term Care has nowhere near the resources required to do anything like real-time analysis of claims as they come in – except to detect the grossest forms of fraud. (Apparently there is some mechanism in place to check for repeats of “once in a life-time” procedures – so if someone tries to bill for an appendectomy on a patient, that patient’s records will be checked to see if anyone has previously billed for an appendectomy on that person.) But beyond this sort of simplistic stuff, there is nothing going on. At the same time, every single payment made is logged, recorded and saved forever – and the data is made available to researchers (it has significant value for clinical research). I’ve talked to people who do academic work on the use of advanced data analytics for fraud and corruption detection, and they were positively salivating at the prospect of getting access to the OHIP data.
Better data analytics also holds out the promise of betting management of claims, and even has the potential improve relations with physicians. As I put it in the paper:
The availability of sophisticated data analysis techniques, combined with electronic record-keeping and inexpensive computing power is no doubt making it much easier for OHIP and other insurers to detect fraud (using such packages as IBM’s Fraud and Abuse Management System [FAMS]) Certain fiddles, which cannot be detected in any individual instance, will nevertheless generate a suspicious pattern of billings, which large-scale data analysis can easily detect… In effect, data analysis has the potential to significantly reduce the information asymmetries between physicians and insurers. Many fiddles are possible only because OHIP processes and assesses claims one at a time. Historically, the audit is the only context in which the larger pattern of claims will be examined. Cheap computing power makes it possible to bridge this gap, by implementing constant, real-time analysis of the pattern of claims. This can be used to enhance enforcement efforts against actual fraud, but it could also be used to develop a rating system for physicians that reflects how aggressive their billing practices are. These ratings could be dynamically adjusted in a completely automated fashion. Physicians who score higher in “aggressivity” could expect closer scrutiny of their claims and stricter interpretation of the rules. This would, in turn, reward honest and forthright billing practices by promising that trustworthiness would be repaid with a higher level of trust.
A bit pie-in-the-sky right now, but in the long term it seems to me perfectly feasible.
Do you think it’s possible that the doctors with really high intermediate-minor assessment ratios are providing care to a specific population with more complex medical needs, where consults would nearly always merit an “intermediate” assessment – e.g. palliative care?